IO、文件、NIO【草案二】
本文共 28169 字,大约阅读时间需要 93 分钟。
(这一个章节将讲到Java里面比较重要的一个章节,这里说一句抱歉,因为最近换工作的原因,一直没有时间继续书写教程,不过接下来我会一直坚持写下去的哈,希望大家能够支持。这个章节主要涉及到常用的文件读写,包括高级的文件IO内容——java.nio,因为这些内容在如今的一些项目里面也属于相当常见的一部分,如果有什么遗漏或者笔误的话,希望读者来Email告知:,谢谢!这一部分篇幅可能比前边章节长很多,也是为了保证能够将Java里面IO和文件操作部分内能写的都写入,如果有遗漏希望读者来Email,概念上有混淆的地方请告知,里面有些内容参考了一些原文数据进行了翻译以及思考注解。) 本章目录:
1.IO类相关内容
2.文件和目录
3.文件高级操作
2.文件和目录
i.文件处理类:
Java针对文件处理的时候提供了专用的文件类:File、FileDescriptor、FilePermission、RandomAccessFile,然后配合上边的IO部分的类:FileInputStream、FileOutputStream、FileReader、FileWriter来进行文件的操作,这几个类构成了Java里面常用的文件处理的结构,如果有遗漏的请读者来Email说明: ;Java和C#不一样的有一点就是文件和目录的抽象表示形式并没有分离,C#里面针对文件和目录有单独的类来进行描述,而Java里面统一使用抽象的File表示文件和目录。
[1]File类说明:
该类的定义如下:
public class File extends Object implements Serializable,Comparable<File>
该类是Java里面针对文件和目录的抽象表示形式,这里列举它常用的方法列表以方便读者查阅:
- 判断操作: boolean canExecute():测试某个应用程序是否可以执行,也就是某个文件是否可以针对平台进行执行,该应用程序是一个抽象路径名表示的文件,Linux平台因为我没有用过这个类,估计是.bin、.rpm或者其他格式文件,Windows一般是.exe、.bat和.com文件 boolean canRead():测试某个应用程序是否可以进行读取,也就是某个文件是否可读 boolean canWrite():测试某个应用程序或文件是否可写,这种情况下当文件设置了只读属性过后,若不更改就会返回false boolean isAbsolute():判断该文件的抽象路径名是为一个绝对路径还是相对路径 boolean isDirectory():测试该抽象路径表示的文件是否为一个目录【这里的目录可以理解为常用的语言:文件夹】 boolean isFile():测试该抽象路径表示的文件是否为一个标准文件 boolean isHidden():测试该抽象路径表示的文件是否是一个隐藏文件或者隐藏目录 boolean exists():测试该抽象路径表示的文件或者目录是否存在
- 枚举操作: String[] list():返回一个字符串数组,这些字符串指定了此抽象路径表示的目录下边所有的文件和目录 String[] list(FilenameFilter filter):和上边方法同义,添加了一个过滤器,满足条件是满足所有过滤器定义的 File[] listFiles():返回一个抽象路径数组,该方法操作的结果是枚举目录下边所有的文件列表的抽象路径表示 File[] listFiles(FileFilter filter):返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。 File[] listFiles(FilenameFilter filter):返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录,和上边方法一模一样 static File[] listRoots():列出可用的文件系统根目录 这里说明两点: >第一:listRoots()使用该方法可以列举所有的根目录,其实所有存在于系统的根目录一般情况就是盘符,Linux可能不一样,Windows调用该方法的时候最终的输出列表就是一个盘符名的数组,因为该方法是静态方法,那么这个方法针对的就是所有的文件,针对每一个安装了Java平台的操作系统而言,就是列举文件的根路径清单。读者可以在自己的平台尝试一下自己写一段简单的程序测试测试。 >第二:关于接口FilenameFilter和FileFilter: FileFilter接口 public interface FileFilter(1.2):该接口用于抽象路径的过滤器,只包含了一个方法:boolean accept(File pathname)——该方法用于测试抽象路径名是否包含在某个路径名的列表中 FilenameFilter接口 public interface FilenameFilter(1.0):实现该接口的类实例可用于过滤器文件名,该接口也只包含了一个方法:boolean accept(File dir,String name)——测试指定文件是否包含在某一个文件列表中
- 修改操作: boolean createNewFile():当且仅当不存在该文件名的时候直接创建一个新的空文件,成功返回true,失败返回false static File createTempFile(String prefix,String suffix):在默认的临时目录中创建一个空文件,使用给定的前缀和后缀的生成名称 static File createTempFile(String prefix,String suffix,File directory):在指定的目录中创建一个新的空文件,使用给定的前缀和后缀的生成文件名 boolean delete():删除此抽象路径表示的文件或目录,删除成功返回true,失败返回false void deleteOnExit():在虚拟机终止的时候,请求删除此抽象路径名表示的目录或文件 boolean mkdir():创建此抽象路径名指定的目录 boolean mkdirs():创建此抽象路径名指定的目录,包括所有必须而且不存在的父目录 boolean renameTo(File dest):重新命名该抽象路径表示的文件名
- 属性的设置和获取: 获取属性函数: File getAbsoluteFile():返回此抽象路径名的绝对路径名形式 String getAbsolutePath():返回此抽象路径名表示的文件或者目录的绝对路径字符串 File getCanonicalFile():返回此抽象路径名的规范形式 String getCanonicalPath():返回此抽象路径名的规范形式字符串 long getFreeSpace():返回此抽象路径名指定分区中未分配的字节数 String getName():返回此抽象路径名表示的文件或者目录的名称 String getParent():返回此抽象路径名父目录的路径名字符串,若没有指定父目录则返回null File getParentFile():返回此抽象路径父母路的路径名;如果没有指定父目录则返回null String getPath():将此抽象路径名转换为一个路径名字符串 long getTotalSpace():返回此抽象路径名指定的分区大小 long getUsableSpace():返回此抽象路径指定分区用于此虚拟机的字节数 long lastModified():返回此抽象路径名表示的文件最后一次被修改的时间 long length():返回此抽象路径表示的文件的长度 设置属性函数: boolean setExecutable(boolean executable):设置此抽象路径所有者执行权限的一个便捷方法 boolean setExecutable(boolean executable,boolean ownerOnly):设置此抽象路径名所有者或用户的执行权限 boolean setLastModified(long time):设置最后一次修改的时间 boolean setReadable(boolean readable):设置此文件为所有者的读权限的一个便捷方法 boolean setReadable(boolean readable,boolean ownerOnly):设置此抽象路径名的所有者或所有用户的读权限。 boolean setReadOnly():标记此抽象路径名指定的文件或目录,从而只能对其进行读操作。 boolean setWritable(boolean writable):设置此抽象路径名所有者写权限的一个便捷方法。 boolean setWritable(boolean writable,boolean ownerOnly):设置此抽象路径名的所有者或所有用户的写权限。
【*:这里还没有列举的方法请读者去查看Java的API文档!】
[2]FileDescriptor类:
文件描述符的实例用作与基础机器有关的某种结构的不透明句柄,该结构表示开放文件、开放套接字或者字节的另一个源或接受者,文件描述符的主要实际用途是创建一个包含该结构的FileInputStream和FileOutputStream,应用程序不应该创建自己的文件描述符。该类构造的时候构造的是一个无效的对象,真正要使用的话还需要斟酌,这里提供一个网上摘录文章的片段【自己翻译】:
其实Sun公司在设计这个类的时候是不希望我们去用它的,参阅官方文档可以知道这个类没有办法构造一个合法的实例对象,也就是说在应用程序里面没有办法创建一个合法的FileDescriptor类的实例。文档里面有显示声明:“Applications should not create their own file descriptors”。
这里针对File descriptor(文件描述符:可能这里翻译的不是很妥当)做个说明:在计算机编程里面,一个文件描述符是去操作这个文件的一个抽象的键,这个用法以前是使用在POSIX结构的操作系统上的,在Windows上边,如果要实现它使用的则是标准C的输入输出库,“file handle”文件句柄。在POSIX系统上边,文件描述符实际上是一个int类型的值,标准C里面就是一个int。在每一进程里面,文件描述符有三个标准的POSIX平台的规范:
标准输入(stdin):值是0
标准输出(stdout):值是1
错误输出(stderr):值是2
其结构如下图:
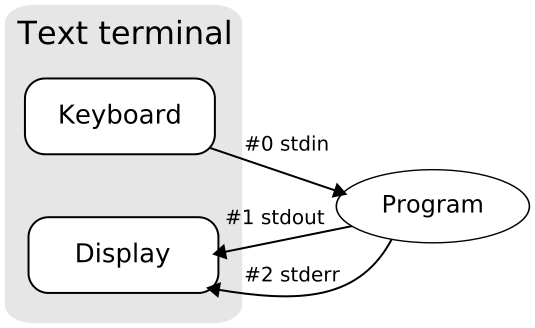
一般来讲,文件描述符在打开文件过程中是系统内核的实体里面整个文件结构的一个索引,它描述了文件内部的数据结构的细节。
——在POSIX结构的操作系统上,这个数据结构又称为文件描述符表,每一个运行进程也有它自己内置的文件描述符表,当用户运行某个应用程序的时候,就是传递一个抽象的Key也就是这个文件描述符给系统内核来实现系统调用,然后内核就通过该系统应用程序的识别和判断来返回一个信号给应用程序告诉它它是否可以操作该文件,这些运行都是基于文件描述符进行的,而应用程序本身是不能实现针对文件描述符表的直接读写操作的。
——在Unix体系结构的操作系统里面,文件描述符可以直接引用文件、目录、块和字符设备(也称为“特殊文件”)、端口、FIFOs(也称为命名管道),而FILE *文件句柄在C的标准库里面就是一个被routines库引用的指针用来管理文件的数据结构而存在,其中这个数据结构往往包括了低级文件描述符用来访问Unix操作系统底层的对象。
——在Windows操作系统里面,同样使用文件句柄来因引用许多底层构造,和POSIX系统的文件描述符一样,微软的C库里面同样提供了兼容功能兼容运行POSIX上边支持的整数值。
【*:好了,不扯远了,否则就没法继续了!】
[3]FilePermission类: 该类的定义为:
public final class FilePermission extends Permission implements Serializable
此类表示对文件和目录的访问,该类的实例由路径名和对该路径名有效的操作组合而成,路径名是授予指定操作的文件或目录的路径名。以 "/*"(其中 "/" 是文件分隔符字符,即 File.separatorChar)结尾的路径名指示包含在该目录中的所有文件和目录。以 "/-" 结尾的路径名(递归地)指示包含在该目录中的所有文件和子目录。由特殊标记 "<<ALL FILES>>" 组成的路径名可匹配任何文件。注:由单个 "*" 组成的路径名指示当前目录中的所有文件,而由单个 "-" 组成的路径名指示当前目录中的所有文件,并(递归地)指示包含在当前目录中的所有文件和子目录。将所要授予的操作以字符串的形式传递给构造方法,该字符串包含由一个或多个用逗号分隔的关键字组成的列表。可能的关键字有 "read"、"write"、"execute" 和 "delete"。其含义定义如下:
read 读权限
write 写权限
execute 执行权限。允许调用 Runtime.exec。对应于 SecurityManager.checkExec。
delete 删除权限。允许调用 File.delete。对应于 SecurityManager.checkDelete。
处理前会将操作字符串转换为小写字母。在授予 FilePermission 权限时要小心。在对各种文件和目录授予读访问权和(尤其是)写访问权时,一定要慎重。对写操作授予 "<<ALL FILES>>" 权限特别危险。这允许对整个文件系统进行写操作。事实上它甚至允许对系统中的二进制文件(包括 JVM 运行时环境)进行替换。
[4]RandomAccessFile类:
该类的定义为:
public class RandomAccessFile extends Object implements DataOutput,DataInput,Closeable
该类的实例支持对随机访问文件的读取和写入,随机访问文件的行为类似存储在文件系统中的一个大型的byte数组,存在指向该隐含数组的光标或索引,称为文件指针;输入操作从文件指针开始读取字节,并随着对字节的读取而前移此文件指针,如果随机访问文件以读取/写入模式创建,则输出操作也可用;输出操作从文件指针开始写入字节,并随着对字节的写入而前移该指针。写入隐含数组的当前末尾之后的输出操作导致该数组的扩展,该文件可以通过getFilePointer方法读取,并且通过seek方法设置。通常,此类中所有的读取例程在读取所需数量的字节之前已经到达了文件末尾,则抛出EOFException,若有些原因无法读取任何字节,而不是在读取所需数量的字节之前已到达文件末尾则抛出IOException,而不是EOFException,特别指出,如果流被关闭了也可能抛出IOException。
该对象的文件位置指针遵循下边几个规律:
- 新建RandomAccessFile对象的文件位置指针位于文件的开头处;
- 每次读写操作之后,文件位置的指针都相应后移到读写的字节处;
- 可通过getFilePointer()方法来获得文件位置指针的位置,通过seek方法来设置文件指针的位置。
——[$]随机的IO访问——
package org.susan.java.io;
import java.io.IOException;
import java.io.RandomAccessFile;
public class RandomIOApp {
public static void main(String args[]) throws IOException{
RandomAccessFile file = new RandomAccessFile("D:/test.txt","rw");
file.writeBoolean(true);
file.writeInt(123456);
file.writeChar('j');
file.writeDouble(1234.56);
file.seek(1);
System.out.println(file.readInt());
System.out.println(file.readChar());
System.out.println(file.readDouble());
file.seek(0);
System.out.println(file.readBoolean());
file.close();
}
}
这段代码的输出为:
123456
j
1234.56
true
不仅仅如此,test.txt文件里面的内容也被写入了,我在书写该程序的时候犯了个小错误,就是第一个file.seek(1)没有调用,所以第一次运行的时候抛了一个EOFException,因为文件的光标没有移动到前边,所以默认是为没有任何字节可以读取了。下边再提供一个比较简单的例子来说明这个类的使用。【*:这里给读者道个歉,因为不知道怎么描述这个类,只能用简单的使用来操作,这是我个人水平的问题,因为平时有时候只是使用到这个类,并没有用得很多。】
——[$]另外简单的用法——
package org.susan.java.io;
import java.io.RandomAccessFile;
public class RandomAccessFileMain {
public static void main(String args[]) throws Exception{
RandomAccessFile file = new RandomAccessFile("D:/test.html","rw");
for( int i = 0; i <= 6; i++ ){
System.out.println(file.readLine());
}
long current = file.getFilePointer();
file.seek(current + 0);
file.write("34".getBytes());
for( int i = 0; i <= 6; i++ ){
System.out.println(file.readLine());
}
current = file.getFilePointer();
file.seek(current + 6);
file.write("27".getBytes());
file.close();
}
}
这里就不介绍这段代码的输入输出了,对了,如果这个地方出现了乱码问题就牵涉到本身读写的系统字符集相关问题,这个在后边的编码章节慢慢解释
——[$]翻译字符——
package org.susan.java.io;
import java.io.File;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
public class TranslationApp {
public static void main(String args[]) throws Exception {
File infile = new File("D:/test.txt");
File outfile = new File("D:/data2.txt");
RandomAccessFile inraf = new RandomAccessFile(infile, "r");
RandomAccessFile outraf = new RandomAccessFile(outfile, "rw");
FileChannel finc = inraf.getChannel();
FileChannel foutc = outraf.getChannel();
MappedByteBuffer inmbb = finc.map(FileChannel.MapMode.READ_ONLY, 0,
(int) infile.length());
Charset inCharset = Charset.forName("ISO8859-1");
Charset outCharset = Charset.forName("utf8");
CharsetDecoder decoder = inCharset.newDecoder();
CharsetEncoder encoder = outCharset.newEncoder();
CharBuffer cb = decoder.decode(inmbb);
ByteBuffer outbb = encoder.encode(cb);
foutc.write(outbb);
inraf.close();
outraf.close();
}
}
这段代码使用了后边将会提及到的java.nio包里面的内容,暂时在这里做一个简单的铺垫
ii.目录处理:
【*:接下来进入文件处理的常用方法里面,首先是针对目录的操作,其次就是处理各种文件,这里仅仅局限于文本文件的处理,更加深入的内容后边会说明,这两部分直接用代码说明。】
——[$]目录的创建、删除——
package org.susan.java.io;
import java.io.File;
import java.io.IOException;
public class DirCreateDelete {
public static void main(String args[]) throws IOException{
File file = new File("D:/test");
if(!file.exists()){
file.mkdir();
}
boolean delResult = file.delete();
if( delResult){
System.out.println("Delete Success!");
}else{
System.out.println("Delete Failure!");
}
}
}
我这里进行了这样的测试,如果D盘下边什么东西都没有这段代码只是会输出Delete Success!,然后运行结束过后D盘下边没有任何内容,表面上看起来好像该程序没有起到任何作用,实际上这个程序已经演示了两个操作,第一个操作是创建了一个名为test的目录,也就是文件夹,其次把这个文件目录删除掉了。【*:当然前提条件是应用程序拥有这个权限进行这两步操作】;然后把后半部分删除目录注释掉单独运行,然后就会发现D盘下边会多一个目录,名称就为test,这样一个目录就创建好了,然后放一个文件到这个目录下,任何文件都可以,再重新取消掉注释——运行,就会发现会输出Delete Failure。这里需要注意的一点就是——使用程序进行File类的delete操作的时候,若File类对象是一个目录,这个目录必须是空目录delete才能成功执行,即使打开了该目录但是程序执行了,这个目录还是会被删除掉。读者可以根据需要设置不同的情况测试上边的程序就能更加理解目录的创建和删除等操作了。
执行下边这段程序之前先做一个简单操作:
创建一个目录以及它的子目录,其结构如下:
root
|—a
|—a1
|—a2
|—a21.txt
|—a3
|—a4.txt
|—b
|—b1
|—b11.txt
|—b2.txt
|—b3
|—c.txt
并且隐藏c.txt,将b11.txt设置成为只读属性
——[$]递归枚举以及属性获取——
package org.susan.java.io;
import java.io.File;
import java.io.IOException;
public class ListFilesTester {
public static void main(String args[]) throws Exception{
File file = new File("D:/root");
listAll(file);
}
/**
* 打印所有输入目录下边的目录和文件以及相关属性
* @param dir
*/
public static void listAll(File dir) throws IOException{
System.out.println("-----------------");
printDir(dir);
if(dir.isDirectory()){
String[] children = dir.list();
for(String child: children){
listAll(new File(dir, child));
}
}
}
public static void printDir(File dir) throws IOException{
System.out.println("Location:" + dir.getAbsolutePath());
System.out.print("[Type: " + (dir.isDirectory()?"Directory":"File") + "],");
System.out.print("[Size:" + dir.length()+ "],");
System.out.print("[Name: " + dir.getName()+ "],");
System.out.print("[CanonicalPath: " + dir.getCanonicalPath()+ "],");
System.out.print("canRead: " + dir.canRead()+ "],");
System.out.print("canWrite: " + dir.canWrite()+ "],");
System.out.println("isHidden: " + dir.isHidden()+ "]");
}
}
然后就会得到下边的输出:
-----------------
Location:D:/root
[Type: Directory],[Size:0],[Name: root],[CanonicalPath: D:/root],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/a
[Type: Directory],[Size:0],[Name: a],[CanonicalPath: D:/root/a],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/a/a1
[Type: Directory],[Size:0],[Name: a1],[CanonicalPath: D:/root/a/a1],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/a/a2
[Type: Directory],[Size:0],[Name: a2],[CanonicalPath: D:/root/a/a2],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/a/a2/a21.txt
[Type: File],[Size:0],[Name: a21.txt],[CanonicalPath: D:/root/a/a2/a21.txt],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/a/a3
[Type: Directory],[Size:0],[Name: a3],[CanonicalPath: D:/root/a/a3],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/a/a4.txt
[Type: File],[Size:11],[Name: a4.txt],[CanonicalPath: D:/root/a/a4.txt],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/b
[Type: Directory],[Size:0],[Name: b],[CanonicalPath: D:/root/b],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/b/b1
[Type: Directory],[Size:0],[Name: b1],[CanonicalPath: D:/root/b/b1],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/b/b1/b11.txt
[Type: File],[Size:0],[Name: b11.txt],[CanonicalPath: D:/root/b/b1/b11.txt],canRead: true],canWrite: false],isHidden: false]
-----------------
Location:D:/root/b/b2.txt
[Type: File],[Size:0],[Name: b2.txt],[CanonicalPath: D:/root/b/b2.txt],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/b/b3
[Type: Directory],[Size:0],[Name: b3],[CanonicalPath: D:/root/b/b3],canRead: true],canWrite: true],isHidden: false]
-----------------
Location:D:/root/c.txt
[Type: File],[Size:0],[Name: c.txt],[CanonicalPath: D:/root/c.txt],canRead: true],canWrite: true],isHidden: true]
上边这个例子递归部分可以修改以适合真正在操作过程中的需求,其他打印部分是为了说明概念而使用,关于目录的部分就说这么多,还有一个例子可以让读者自己去思考:如何用程序递归删除一个目录,可以尝试做做!
iii.文件处理:
关于文件的处理部分不简介和目录一样的创建删除以及递归读取,主要是针对File类和IO部分讲解文件的读取以及写入。
[1]文本文件的输入输出
当程序在保存数据的时候,一般情况下有两种数据格式可以选择:二进制数据和文本格式。举个例子,如果有一个整数:1234,如果使用二进制数据进行读写就是:00 00 04 D2,如果是按照文本格式进行读写,就直接保存为“1234”,当然理论上讲,二进制IO的读写是很快很高效的,但是它保存的数据的可读性很差,所以在读写文件的时候需要注意文件中数据的格式的选择。而针对文本数据的读写,虽然读写效率不如二进制数据,但是可读性很好,但是文本文件的输入输出需要考虑另外一个问题:就是字符编码问题。一般情况下,英文操作系统的默认系统编码字符集一般是latin1,也就是ISO8859-1(cp1252)的编码字符集,中文系统的默认系统编码字符集一般是GB18030或者是GBK和GB2312。
OutputStreamWriter类是在高级流到低级流中做桥梁使用的,这个类型在读写字符的时候字节的编码是Unicode编码格式,同样的InputStreamReader类在传输数据的时候也是使用的Unicode编码格式操作的,这一点需要铭记。
【*:Java的IO体系结构里面需要了解的是,每一个类可以当作一个IO的读写通道,而读写通道之间是可相互连接的,不论是包装的方式连接、还是桥梁的方式连接、或者普通连接方式(普通方式就类似于输入和输出直接连接在一起,或者使用一个过滤链进行连接),它们都是可以作为读写通道连接的。需要了解的还有一点:就是什么类可以直接连接输入源和输出源,这一点写的程序多了自然就可以了解了,希望读者自己尝试。但是有些类读者可以记住是不能直接连接输入输出源的,首先就是做桥梁使用的InputStreamReader和OutputStreamWriter,这两个类因为是高级流和低级流之间的桥梁,而且是单向的,那么它的输入必须是一个InputStream或者OutputStream,而输出必须是Reader和Writer中的其中一个实例。其次包装使用的四个类貌似也不行,不过我没有验证过,就是:BufferedOutputStream、BufferedInputStream、BufferedWriter、BufferedReader;所以在学习Java IO系统的时候,只要搞清楚每一个类它的连接作用,那么就可以直接通过设置以及构造的方式创建从应用程序IO到系统IO的读写通道——这里的读写通道不是指代某个类,就是这些类全部连接到一起,从一个定义的输入源到属出源完整的不带任何异常的整体读写通道。这里可能很难理解,等到看到下边的一些代码示例过后就知道了。】
——[$]直接读写(FileReader和FileWriter)——
package org.susan.java.io;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class DirectCopyMain {
public static void main(String args[]) throws IOException{
File inputFile = new File("D:/read.txt");
File outputFile = new File("D:/write.txt");
FileReader in = new FileReader(inputFile);
FileWriter out = new FileWriter(outputFile);
int c;
while((c = in.read())!= -1){
out.write(c);
}
in.close();
out.close();
}
}
这段程序没有任何输出在控制台,只是运行过后,D盘(也就是上边File构造的路径)下边会有一个write.txt文件生成,里面的内容和read.txt一模一样,当然前提是D盘下边有个read.txt。不过这样直接读写有一个问题,就是中文很可能出现乱码,这是read.txt和write.txt里面的内容清单:
read.txt文件内容:
你好
Hello World
write.txt文件的内容:
���
Hello World
Windows从Vista开始提供了read.txt的保存编码格式,XP下边我不是很清楚,因为很久没有使用过了,一般情况下记事本里面的文本可以保存为四种格式,这里提供这四种格式的不同输出:
ANSI格式:
���
Hello World
Unicode格式:
��`O}Y H e l l o W o r l d
Unicode big endian格式:
��O`Y} H e l l o W o r l d
UTF-8格式:
你好
Hello World
这里提供我系统本身的环境以供读者参考:我操作系统是英文版,但是我不知道默认编码是什么格式,照理说应该是UTF-8的,因为我设置过,包括Eclipse里面的编辑器编码格式以及Eclipse里面Console输出的编码格式。
【这部分是分析以及猜测,非确定性概念*:这里提供一个编程经验,因为我自己平时开发的时候使用的是编码统一,所以我建议所有的开发者在开发过程中尽量保证编码统一。一般情况下,Java语言、MySQL、Tomcat服务器的默认编码是latin1的,也就是ISO8859-1(cp1252)的,这种编码格式是标准的北欧英文编码的一种规范,这种格式对中文的支持不是太好,所以在使用过程最好能够统一编码,而操作系统、开发平台、服务器、应用程序、测试平台以及数据库最好能够统一编码,这样对中文开发更加有效而且更加便捷。因为我操作系统默认编码是UTF-8,所以上边的文章里面当我的txt文件使用的是UTF-8编码格式的时候,中文乱码就没有了,因为里面没有出现过转码操作。按照逻辑推理,必须要保证的一点是:如果一个文本数据本身在保存的时候形成文件使用了什么编码,那么最终输出的编码也最好能够统一,而且中间转码的时候最好是形成一个对称转换。比如一个文本:ISO8859-1的格式,经历转码过程:ISO8859-1->UTF-8->GBK->UTF-8->ISO8859-1,按照这样的过程,最终输出的环境如果是ISO-8859-1的,那么最终显示的文本应该不会有乱码,但是会有特殊情况就是针对中文的,在编程过程,中文最好使用UTF-8或者GBK(GB2312)的格式,否则真正在使用过程会出现一些不必要的时间开销。还有一点特别说明:在你眼睛看到文本的显示的时候,注意你打开该文本的应用程序本身编辑器的格式,包括Eclipse、MySQL Front、Navicat这种IDE,因为有可能文本本身的格式没有问题,但是IDE的格式会造成视觉上的不同步,就使得我们把原本正确的程序反而调错了,当然这些只是经验之谈,没有其他的确定性证据来证明。这部分概念请三思!】
——[$]换一种方式读写(FileOutputStream和FileInputStream)——
package org.susan.java.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class StreamDirectCopyMain {
public static void main(String args[]) throws IOException{
File inputFile = new File("D:/read.txt");
File outputFile = new File("D:/write.txt");
FileInputStream in = new FileInputStream(inputFile);
FileOutputStream out = new FileOutputStream(outputFile);
int c;
while((c = in.read())!= -1){
out.write(c);
}
in.close();
out.close();
}
}
运行这段程序可以看见和上边使用高级流的程序的差异,就是乱码问题没有了,因为使用低级流使用的是字节输入输出,使用字节输入输出的时候,编码是可以设置的,这个问题稍候详细讨论。这里总结几点需要说明:
- 上边这两个程序都是直接读写,源和目标设备都是操作系统中的文件
- 如果使用Java IO读取写入文件的时候,一定要考虑字符的编码问题,其实主要是非北欧文字需要考虑,比如中文、日文、韩文等
- FileReader、FileWriter、FileInputStream、FileOutputStream这四个类上边程序使用的构造传入的参数是File类,但是还有一种构造是直接使用String类型,这个String类传入的是文件路径
所以必要的时候需要使用转码方法以及带编码的构造方式,这里提供一些常用的代码段:
InputStreamReader in = new InputStreamReader(new FileInputStream("D:/read.txt"),"ISO8859_1");
这种格式在读取文件的时候会自动转换里面内容的编码,注意:编码构造只有桥梁操作的类存在,而字符流本身不会存在带编码的构造,而字节流本身也不存在这种构造方式。这里看看InputStreamReader和OutputStreamWriter的构造方法:
InputStreamReader的构造方法: InputStreamReader(InputStream in):创建一个使用默认字符集的InputStreamReader
InputStreamReader(InputStream in,Charset cs):创建一个使用给定字符集的InputStreamReader
InputStreamReader(InputStream in,CharsetDecoder dec):创建一个使用给定字符集解码器的InputStreamReader
InputStreamReader(InputStream in,String charsetName):创建一个使用给定字符集名称的InputStreamReader
OutputStreamWriter的构造方法:
OutputStreamWriter(OutputStream out):创建一个使用默认字符集的OutputStreamWriter
OutputStreamWriter(OutputStream out,Charset cs):创建一个使用给定字符集的OutputStreamWriter
OutputStreamWriter(OutputStream out,CharsetEncoder enc):创建使用给定字符编码器的OutputStreamWriter
OutputStreamWriter(OutputStream out,String charsetName):创建一个使用给定字符集名称的OutputStreamWriter
——[$]缓冲读写——
package org.susan.java.io;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
public class BufferFileProcessor {
public static void main(String args[]) throws Exception{
FileReader inReader = new FileReader("D:/read.txt");
FileWriter outWriter = new FileWriter("D:/write.txt");
BufferedReader in = new BufferedReader(inReader);
BufferedWriter out = new BufferedWriter(outWriter);
int c = 0;
while((c = in.read()) != -1){
out.write(c);
}
in.close();
out.close();
}
}
这个地方和上边不一样的就是:这个地方的读写经过了包装,在Reader和Writer之外经过了缓冲读写通道的包装,这样的读写速度在处理大文件的时候速度比直接读写快,这个前边已经说明了。这里还需要注意一点就是:
- 缓冲区针对读写通道的包装可以是单向的,也就是说上边的程序可以改写,就是不使用out来进行输出,直接使用outWriter进行输出操作,这种操作也可以运行,但是性能有待斟酌,这里可以证明一点的就是:包装类的作用只是针对原来的读写通道进行了一层装饰,有和没有都不会影响到输入输出的成功与否,Java API里面提供的缓冲输入输出类只是针对这些进行了性能改善,所以理解了这点过后就可以理解下边这段程序同样可以成功读写的原因:
——[$]仅提供缓冲读取——
package org.susan.java.io;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.FileWriter;
public class BufferFileProcessor {
public static void main(String args[]) throws Exception{
FileReader inReader = new FileReader("D:/read.txt");
FileWriter outWriter = new FileWriter("D:/write.txt");
BufferedReader in = new BufferedReader(inReader);
//BufferedWriter out = new BufferedWriter(outWriter);
int c = 0;
while((c = in.read()) != -1){
outWriter.write(c);
}
in.close();
outWriter.close();
}
}
——[$]StringReader和StringWriter——
package org.susan.java.io;
import java.io.IOException;
import java.io.StringReader;
import java.io.StringWriter;
public class StringIOApp {
public static void main(String args[]) throws IOException{
StringWriter outWriter = new StringWriter();
String str = "This is a test.";
for( int i = 0; i < str.length(); ++i){
outWriter.write(str.charAt(i));
}
System.out.println("Outstream: " + outWriter);
System.out.println("Size: " + outWriter.toString().length());
StringReader inReader;
inReader = new StringReader(outWriter.toString());
int ch = 0;
StringBuilder builder = new StringBuilder();
while((ch = inReader.read()) != -1){
builder.append((char)ch);
}
str = builder.toString();
System.out.println(str.length() + " characters were read");
System.out.println("They are: " + str);
}
}
这段代码的输出为:
Outstream: This is a test.
Size: 15
15 characters were read
They are: This is a test.
这里简单演示了StringReader和StringWriter的用法,如果要知道详细的用法请读者自己查阅一下Java API。
[2]操作压缩文档(Zip、Jar、GZip)
【Zip文档的读写(.zip)】
Zip压缩格式:ZIP是一个计算机文件的压缩算法,原名Deflate,是一种相当简单的分别压缩每个文件的存档格式,分别压缩文件允许不必读取另外的数据而检索独立的文件;理论上,这种格式允许对不同的文件使用不同的算法,但是不管使用什么方法,对这种格式的告诫是对于包含很多文件的时候,存档会明显的比压缩成一个独立的文件要大。ZIP的规约指出文件可以不经压缩或者使用不同的压缩算法来存储,然而实际上ZIP几乎都是使用的DEFLATE算法。不仅仅如此,ZIP支持基于对称加密的简单的密码,现在却存在了严重的缺陷,ZIP格式的文件也支持分卷。
在Java语言里,可以使用ZipInputStream来读取一个ZIP文件,在这些文件里面存在独立的entries(实体集)的概念,可以使用ZipEntry来描述里面的每一个实体,在读取ZIP文件的时候如果出现了错误就会抛出ZipException错误,中断、关闭、错误数据、未知格式、数据不完整都有可能导致Error使得程序抛出ZipException。先看一个例子来读取Zip文件:
——[$]读取一个Zip文件——
package org.susan.java.io;
import java.io.FileInputStream;
import java.util.zip.ZipEntry;
import java.util.zip.ZipInputStream;
public class ZipReader {
public static void main(String args[]) throws Exception{
ZipInputStream zin = new ZipInputStream(new FileInputStream("D:/root.zip"));
ZipEntry entry;
while((entry = zin.getNextEntry())!=null){
System.out.println(entry.getName());
}
zin.close();
}
}
这里把上边演示的例子里面创建的root文件压缩成为一个root.zip的包,读取其基本信息,输出为下:
root/
root/a/
root/a/a1/
root/a/a2/
root/a/a2/a21.txt
root/a/a3/
root/a/a4.txt
root/b/
root/b/b1/
root/b/b1/b11.txt
root/b/b2.txt
root/b/b3/
root/c.txt
从上边可以看到Zip文件读取成功,而且把里面的清单全部打印出来了。ZipInputStream可以读取文件的序列,也就是说读出这个文件压缩了多少文件,而Java API还提供了另外一个类:ZipFile,这个类是使用的内嵌的随机文件读取读出文件的内容,所以不是顺序读取,这两个类的区别就在这里,改写一下上边这段程序而实现解压的功能:
——[$]使用Java解压——
package org.susan.java.io;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.util.Enumeration;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
public class UnZipReader {
public static void main(String args[]) throws Exception{
String fileFrom = "D:/root.zip";
String unZipDir = "D:/root1";
unZip(fileFrom, unZipDir);
}
/**
* 解开压缩文件,将某个文件解压
* @param fileFrom
* @param unZipDir
*/
@SuppressWarnings("unchecked")
public static void unZip(String fileFrom,String unZipDir){
try{
File file = new File(unZipDir);
if(!file.exists()){
file.mkdirs();
}
BufferedOutputStream dest = null;
BufferedInputStream in = null;
ZipEntry zipEntry;
ZipFile zipFile = new ZipFile(fileFrom);
Enumeration enumeration = zipFile.entries();
while(enumeration.hasMoreElements()){
zipEntry = (ZipEntry)enumeration.nextElement();
System.out.println("Extraction: " + zipEntry);
if(zipEntry.isDirectory()){
System.out.println(unZipDir + "/" + zipEntry.getName());
makeDir(unZipDir + "/" + zipEntry.getName());
}else{
in = new BufferedInputStream(zipFile.getInputStream(zipEntry));
int count;
byte bufferData[] = new byte[2048];
FileOutputStream fos = new FileOutputStream(unZipDir + "/" + zipEntry.getName());
dest = new BufferedOutputStream(fos);
while((count = in.read(bufferData, 0, 2048)) != -1){
dest.write(bufferData, 0, count);
}
dest.flush();
dest.close();
in.close();
}
}
}catch (Exception e) {
e.printStackTrace();
}
}
/**
* 解压缩出来过后如果目录不存在就需要创建新目录
* @param unZipDir
* @return
*/
private static boolean makeDir(String unZipDir){
boolean result = false;
try{
File file = new File(unZipDir);
if(!file.exists()){
result = file.mkdirs();
}
}catch(Exception ex){
ex.printStackTrace();
result = false;
}
return result;
}
}
执行这段程序就将root.zip里面的文件全部解压出来了,而且控制台会有以下输出:
Extraction: root/
Extraction: root/a/
Extraction: root/a/a1/
Extraction: root/a/a2/
Extraction: root/a/a2/a21.txt
Extraction: root/a/a3/
Extraction: root/a/a4.txt
Extraction: root/b/
Extraction: root/b/b1/
Extraction: root/b/b1/b11.txt
Extraction: root/b/b2.txt
Extraction: root/b/b3/
Extraction: root/c.txt
这段程序和最初的那段不一样就是这一段不仅仅在控制台有输出,而且会发现目标目录下边多了一个文件夹root1,而且里面的文件目录结构就是压缩包root.zip里面的文件结构,也就是说这个程序针对root.zip进行了解压操作。【*:不过有一点需要说明,在解压过程中需要做一个判断,就是代码里面的这句话:zipEntry.isDirectory(),如果不做判断这段代码就会抛出IOException。网上有些代码没有做判断,是因为它的压缩包里面没有目录存在,全都是压缩文件,一旦这个压缩包里面存在目录的话,那么目录只能依靠mkdirs来创建,而不能使用FileOutputStream来操作,读者可以试试把这个判断条件改成始终false就可以看到有什么结果出来了,这个地方需要简单提醒。可以这样理解:解Zip压缩包的时候,文件可以通过ZipEntry的getInputStream以流的方式进行读取,但是目录最好使用mkdirs,这里不用多说,读者尝试修改代码里面的内容就可以理解这段话的意思了!】
这里还需要说明一点:ZipInputStream和ZipFile之间另外有一个基本的不同点在于:当文件是用ZipInputStream和ZipOutputStream的时候,ZIP条目不使用高速缓存,然而如果使用的是ZipFile来打开文件的话,它会使用内嵌的高速缓存,所以如果ZipFile被重复调用的话文件只可以被打开一次,缓冲值将会在第二次打开的时候使用,也可以这样讲使用ZipFile优于ZipInputStream。
下边一段程序就演示Java用程序压缩某个文件夹的过程:
——[$]压缩某个文件夹——
package org.susan.java.io;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import org.apache.tools.zip.ZipEntry;
import org.apache.tools.zip.ZipOutputStream;
public class CompressZipWriter {
public static void main(String args[]) throws Exception {
compressZip("D:/work/test", "D:/work/test1.zip");
}
/**
* 压缩的主过程,从一个源目录压缩整个文件夹到目标ZIP文件
* @param source
* @param dest
* @throws Exception
*/
private static void compressZip(String source, String dest)
throws Exception {
File baseFolder = new File(source);
if (baseFolder.exists()) {
if (baseFolder.isDirectory()) {
List<File> fileList = getSubFiles(new File(source));
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(dest));
zos.setEncoding("GBK");
ZipEntry entry = null;
byte[] buf = new byte[2048];
int readLen = 0;
for (int i = 0; i < fileList.size(); i++) {
File file = fileList.get(i);
// 这里写入这样的判断是为了能够压缩空目录
// 某个目录没有东西需要压缩就下边这句判断
if (file.isDirectory()) {
entry = new ZipEntry(getAbsFileName(source, file) + "/");
} else {
entry = new ZipEntry(getAbsFileName(source, file));
}
entry.setSize(file.length());
entry.setTime(file.lastModified());
zos.putNextEntry(entry);
if (file.isFile()) {
InputStream in = new BufferedInputStream(new FileInputStream(file));
while ((readLen = in.read(buf, 0, 1024)) != -1) {
zos.write(buf, 0, readLen);
}
in.close();
}
}
zos.close();
} else {
throw new Exception("Can not do this operation!.");
}
} else {
baseFolder.mkdirs();
compressZip(source, dest);
}
}
/**
* 获取一个目录下边的所有子目录和文件
* @param baseDir
* @return
*/
private static List<File> getSubFiles(File baseDir) {
List<File> fileList = new ArrayList<File>();
File[] temp = baseDir.listFiles();
for (int i = 0; i < temp.length; i++) {
if (temp[i].isFile()) {
fileList.add(temp[i]);
}
if (temp[i].isDirectory()) {
// 因为要压缩空目录所以这里也需要添加一个File进去
fileList.add(temp[i]);
fileList.addAll(getSubFiles(temp[i]));
}
}
return fileList;
}
/**
* 给定根目录,返回另一个文件名的相对路径,用于zip文件中的路径
* @param baseDir
* @param realFileName
* @return
*/
private static String getAbsFileName(String baseDir, File realFileName) {
File real = realFileName;
File base = new File(baseDir);
String relName = real.getName();
while (true) {
real = real.getParentFile();
if (real == null)
break;
if (real.equals(base))
break;
else {
relName = real.getName() + "/" + relName;
}
}
return relName;
}
}
上边程序就可以把一个源目录下边所有的文件以及文件夹压缩到一个ZIP的压缩文档里面,不过这里有几点需要注意:
- 这里使用了Apache的Ant软件里面的ant.jar,其实我在写的时候只是把zip包下边的源文件直接拷贝过来的,这里怕读者不知道这两个类的出处,因为java.util.zip包里面有两个同名类,方法都类似,下边这个方法是org.apache.tools.zip.ZipOutputStream特有的: zos.setEncoding("GBK");这里这样做的目的是为了中文文件名在压缩的时候不会出现乱码,如果要处理中文问题使用这个包比较方便。
- 这里还需要注意这一句:entry = new ZipEntry(getAbsFileName(source, file) + "/");这句代码的目的就是为了压缩空目录而操作的,虽然有时候空目录放入一个压缩包没有特别的意义,但是为了保证程序的完整性,这样的压缩才算是正确的压缩操作,在打包文件进入一个ZIP格式的压缩文档的时候,即使是一个空目录也需要把文件夹压缩进去。后缀带“/”在调用putNextEntry方法的时候,该包会自动创建一个目录而不是文件,否则就会直接创建这个一个文件,使得这个压缩过程出现问题。
- 这段代码输出过后,目录:D:/work目录下边会多一个压缩文件:test1.zip,这个压缩文件里面保存的内容就是source表示的文件夹下边所有的目录文件以及子目录和子文件的集合
【GZip文档的读写(.gz或者.gzip)】
GZIP文件格式和Zip的原理类似,唯一不同的是,这种文件格式主要用于UNIX系统的文件压缩,文件后缀为.gz或者.gzip,这种文件就是GZIP格式的。GZip文件的读写和Zip文件的读写类似,这里就不做过多的说明,我没有测试过不过读者可以自己试试用ZIP同样的方法去读取GZIP文件,看看二者有什么区别。需要注意一点就是,GZIP文件在读写过程使用的类为:GZIPInputStream和GZIPOutputStream两个,这两个的基本用法和ZIP的InputStream以及OutputStream类似,所以应该使用同样的方式可以实现上边代码部分ZIP实现的功能。
转载地址:http://lokws.baihongyu.com/
你可能感兴趣的文章
linux进程之间通讯常用信号
查看>>
main函数带参数
查看>>
PCB布线技巧
查看>>
关于PCB设计中过孔能否打在焊盘上的两种观点
查看>>
PCB反推理念
查看>>
京东技术架构(一)构建亿级前端读服务
查看>>
git 提示:error: unable to rewind rpc post data - try increasing http.postBuffer
查看>>
php 解决json_encode中文UNICODE转码问题
查看>>
LNMP 安装 thinkcmf提示404not found
查看>>
PHP empty、isset、innull的区别
查看>>
apache+nginx 实现动静分离
查看>>
通过Navicat远程连接MySQL配置
查看>>
phpstorm开发工具的设置用法
查看>>
Linux 系统挂载数据盘
查看>>
Git基础(三)--常见错误及解决方案
查看>>
Git(四) - 分支管理
查看>>
PHP Curl发送数据
查看>>
HTTP协议
查看>>
HTTPS
查看>>
git add . git add -u git add -A区别
查看>>